Good Robot! Bad Robot! The Future of Robotic Feedback Deep Learning

Imagine being able to tell a robot “good job” or “job well done.. Right now, if I thank Siri for performing a task correctly, I receive a generic automated “no problem” in return. Robot engineers at the U.S. Army Research Laboratory and the University of Texas at Austin are looking to change that by transforming your human feedback into robotic programming language.
The Deep TAMER Algorithm
Developed by Dr. Peter Stone at the University of Texas at Austin, along with his former doctoral student, Brad Knox, the original Training an Agent Manually via Evaluative Reinforcement (TAMER) algorithm allowed human operators to provide real-time feedback in the form criticism against the robotic performance. The new algorithm, which was presented this month at the Association for the Advancement of Artificial Intelligence Conference in New Orleans, is known as Deep TAMER and uses deep machine learning.

The original Training an Agent Manually via Evaluative Reinforcement (TAMER) algorithm allowed human operators to provide real-time feedback in the form criticism against the robotic performance, influencing the robot’s programming and learning.
Deep machine learning is a class of machine learning inspired by the brain’s learning behavior. It provides the robot with the ability to learn how to perform tasks by viewing video streams in a short amount of time with a human trainer. According to Army researcher Dr. Garret Warnell, the training method is similar to training a dog. The human operator observes the robot and provides positive or negative feedback on how the robot performed. This is an important step for real-time applications, as robot that operate in the real-world will need to recognize, diagnosis, and respond to their changing environment.
According to Knox, TAMER approaches differently learning from human reward in three key ways:
- TAMER addresses delays in human evaluation through credit assignment.
- TAMER learns a predictive model of human reward.
- At each time step, TAMER chooses the action that is predicted to directly elicit the most reward, eschewing consideration of the action’s effect on future state (i.e., in reinforcement learning terms, TAMER myopically values state-action pairs using a discount factor of 0).
Deep TAMER vs. Current Training Methods
The current method of training artificial intelligence (AI) requires robots to interact with their environment repeatedly to learn how to perform a task optimally. The robot will attempt several different movements to achieve the goal and, in doing so, these attempts could have harmful consequences. For example, a robot with AI trying to traverse a bumpy road will try a different speeds and routes to overcome the obstacles. This could lead to the robot running into walls or falling over, since it may not be aware of its surroundings.
With Deep TAMER, the human operator is providing feedback as the robot is self-determining the best method to accomplish the task. In doing so, the human operator is helping to speed up the learning curve and avoid mistakes. The algorithm was demonstrated against an Atari bowling video game. Within 15 minutes of human-provided feedback, the robot algorithm performed better than the human operator. This is a task that has proven difficult for even current state-of-the-art artificial intelligence.
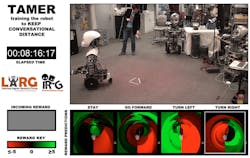
Using a reward based system of +1 and −1, the robot is learning via human feedback how to approach the target with the best method possible in real time.
The TAMER algorithm has also been used in navigation. The research team’s interactive robot navigation test provided reward instances of +1 or −1 in value. In the image above, the rewards are visualized in the bottom-left box labeled “Incoming Reward.” The input features for the TAMER-learned reward model are the action and the distance and angle to the Vicon-tracked marker. The predictive model of human reward learned is displayed in the three squares at the bottom right—from a bird’s-eye perspective of the robotic agent—and the marker. The robot is facing upward and the marker is shown as a white triangle.
The goal is that within the next two years, the research team can expand the learning abilities of the algorithm to other simulation environments that better represent real-world applications. These applications include deployment into the field as bomb detection and search and rescue. “The army of the future will consist of soldiers and autonomous teammates working side-by-side,” Warnell said. “While both humans and autonomous agents can be trained in advance, the team will inevitably be asked to perform tasks—for example, search-and-rescue or surveillance—in new environments they have not seen before.”

