Practical Predictive Maintenance for Machines
Today’s consumers live in a data-driven world where they can easily access information about their homes, cars, banking and much more right from their mobile devices. Similar technologies are becoming available in the manufacturing sector, enabling Industrial Internet of Things (IIoT) applications where users can remotely monitor, analyze and optimize equipment operation. Advanced techniques such as machine learning are being used to improve how machines are operated, analyzed and maintained.
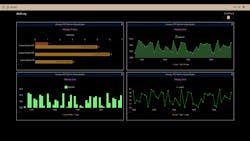
Gathering massive quantities of data, arranging it in spreadsheets and hoping to manually uncover insights is a monumental task with a poor success rate. A smarter and better approach is creating a predictive maintenance (PdM) model where machine data is collected over time, with the goal of finding patterns to predict and prevent future failures, and then depicting this information via dashboards (Fig. 1).
This approach to PdM has conventionally required large, centralized computing resources and applications—along with significant integration and configuration effort. Today, however, there are software applications which are easily configured and can be deployed on machinery at the operational edge to work with cloud-hosted software-as-a-service (SaaS) to provide extensive PdM dashboards.
The PdM Data Analysis Challenge
The goal of any PdM initiative is to predict if the process and/or equipment should undergo preventative maintenance, and when this should be, typically before a failure occurs. This requires:
- Data availability
- Framing the problem
- Evaluating the prediction method
Data acquisition is a vital part of PdM. In order to generate useful insights, data should be gathered as frequently and as widely as possible. Some example datasets for PdM are:
· Equipment details (static data)
· Usage data (frequently updated data)
· Maintenance details (occasionally updated data)
· Time series data (near real-time)
A good dataset is filled with relevant process and/or equipment data of sufficient quantity and quality to produce good understanding and trusted predictions. Lack of data is a frequent issue with industrial automation, but this problem can be overcome by applying certain methods to the available datasets.
Asking the Right Questions
To identify which PdM methods should be used, a series of questions must be answered:
- Which part of the process is essential for good PdM performance?
- What is the desired output from the model?
- Does just one machine require PdM, or is PdM required by the whole operation?
- Is there an appropriate amount of historical data that shows both machine operations and failures?
These questions raise a series of other relevant issues—requiring input from those closest to the systems in question, both operators and equipment manufacturers—along with information gathering about the processes and/or equipment. Typical information includes critical variables, operating thresholds, and data acquisition availability from controllers and sensors.
Once the important information sources are understood, identifying which part of the system is a good candidate for PdM should be clear.
Framing it Up
The next step is to develop an understanding of how the available dataset describes the problem. Operating systems and associated datasets exhibit many types of relationships which are useful for constructing PdM strategies.
Equipment such as motors and pumps may have run-to-failure datasets from the manufacturer. This data projects when healthy operations are likely to cease due to an impending or actual failure requiring maintenance. If no run-to-failure data is available, it is possible to use the company’s service and maintenance data as a basis, provided there is sufficient applicable historical data. Sometimes is makes sense to use limited data, also known as a censored dataset, when a complete lifetime of information is not available, with only portions of interest used.
Another approach is using a “known variable threshold” to set a limit for the PdM algorithm. For example, a motor is most likely to fail when a specific part’s vibration is higher than 50 Hz. The PdM can constantly monitor this variable and predict how much time the motor can run before the variable reaches its threshold.
PdM can also be applied on a larger process-wide scale by monitoring several variables to determine if overall operations are normal, or if there are warning signs of an impending failure. To determine this type of performance, a thorough study must be undertaken to expose which variables have the most impact on the process.
For example, it may be discovered that a pump system is operating under stress leading to failure when its vibration is observed to increase while the flowrate of the system remains constant. Therefore, vibration and flowrate in conjunction are important variables to be monitored.
Choosing the PdM Method
Finally, after data availability is defined and the specific part of the process to be monitored is identified, the PdM method must be chosen. There are a few different types of PdM methods, each one applicable based on the available data and the desired output. This article is concerned with two of the most widely used methods:
- Remaining useful lifetime (RUL) calculation
- Failure detection
Many users want to know “how long before it breaks?” Applying the RUL method to the datasets often involves using regression models to predict RUL. For instance, similarity models may be used when a complete run-to-failure dataset is available and the proper variables can be monitored. The model is constructed with the dataset variables and applied to real-time monitoring, thereby providing an estimated RUL based on the actual data.
Degradation models are based on a variable threshold and are designed to estimate the RUL based on the evolution of this given critical variable. Another example is survival models, which can be applied to datasets that are censored. Survival models can estimate the RUL based on incomplete datasets, using information such as maintenance history and life span to provide the probability of survival of the system.
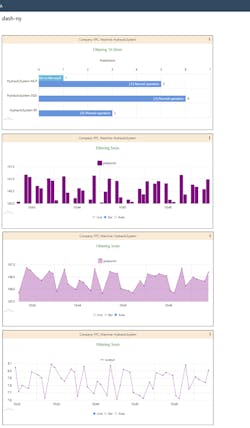
Another popular user question associated with process monitoring asks “is it working normally or is it failing?” This method of choice here is called failure detection, where the PdM model is constructed under normal operations and used to establish a baseline value. The process is constantly evaluated, and if the measured variables deviate too far from the baseline value, this may indicate an impending failure (Fig. 2).
The PdM models described above are mathematical representations of reality based on relatively simple expressions. Newer PdM models are becoming more sophisticated with emerging ML techniques, and these are gaining traction as a more robust way to model complex systems.
PdM Benefits
All of this may sound a little daunting, and it would be if OEMs and end-users needed to develop PdM systems from scratch. Fortunately, edge-deployable and cloud-hosted SaaS software products are available to do the heavy lifting of data gathering, dataset analysis, PdM methodology assignment and visualization/notification.
Using the right suite of software products, creation of a PdM application begins by understanding what kind of data is available, which type of failures need modeling and the type of output expected from the model (Fig. 3). Properly executed PdM programs deliver many benefits:
- Cost savings
- Increased uptime and output
- Prolonged hardware life
- Enhanced product quality
- Reduced waste
- Minimized maintenance costs
Models often need to be retrained so they can learn and map using newly acquired datasets, thereby identifying data trending and model drift. How often the model needs to be retrained depends on the environment and when the statistical data properties change. There are monitoring techniques that can assist in detecting model degradation; applications should be designed to monitor for drift and alarm, and corresponding model degradation.
In today’s data-driven world, modern machines can be equipped with hardware and software technology, making it easy for users and OEMs to implement effective PdM programs.
Gabriel Andrade is a machine learning lead at ADISRA LLC, where he is currently developing ADISRA KnowledgeView, an application focused on process and equipment monitoring.
About the Author
Gabriel Andrade
Machine Learning Lead, ADISRA LLC
Gabriel Andrade is a machine learning lead at ADISRA LLC, where he is currently developing ADISRA KnowledgeView, an application focused on process and equipment monitoring.
Voice Your Opinion!
To join the conversation, and become an exclusive member of Machine Design, create an account today!

Leaders relevant to this article: